xiaowuhello
上的群集服务前
>>
完整版
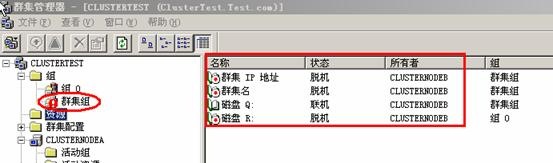
1) 在停止ClusterNodeB上的群集服务前,先打卡群集管理器,可以察看到,目前资源的所有者是ClusterNodeB。
2) 停止ClusterNodeB的群集服务。
3) 再次回到群集管理器,发现资源的所有者已经切换到ClusterNodeA上。因为ClusterNodeB上的服务已停止,不可能自动恢复过来。仍旧通过心跳侦测机制,当丢失4次心跳信息后,(大约5秒),则会宣告该节点失败。所以图中显示红叉,表示ClusterNodeB这个节点目前不可用。
4) 此实验说明,当某个节点上的群集服务停止后,运行在该问题节点上的资源会自动转移到其他正常节点。
(4) 模拟意外断电时故障转移 1) 测试前按照老规矩,打开集群管理器,可以看到资源的所有者是ClusterNodeB。
2) 直接关闭虚拟机后,打开ClusterNodeA上的集群管理器,发现资源已经为脱机状态,且群集组已显示不正常。
3) 群集服务试图将资源所有者切换到ClusterNodeA上。
4) 资源已全部迁移到ClusterNodeA上,且显示ClusterNodeB不正常。
5)此实验说明,当群集中的节点遇到突发性的意外事件(如意外断电等。)后,资源会自动从问题节点转移到正常节点。