虚拟机vmware6.5 搭建win2003双节点cluster
VMware Workstation 6.0中Cluster配置指南
目录
(3) ClusterNodeA上的共享磁盘配置... 12
(5) ClusterNodeB上的共享磁盘配置... 21
一、群集介绍
服务器群集是一组协同工作并运行Microsoft群集服务(Microsoft Cluster Service,MSCS)的独立服务器。它为资源和应用程序提供高可用性、故障恢复、可伸缩性和可管理性。它允许客户端在出现故障和计划中的暂停时,依然能够访问应用程序和资源。如果群集中的某一台服务器由于故障或维护需要而无法使用,资源和应用程序将转移到可用的群集节点上。
(说明:本文档编写的目的是为了帮助大家实现所关心的如何在VMWare Workstation中完成典型群集的配置步骤,不会具体的涉及到如何安装群集应用程序,如Exchange群集等)
二、群集专业术语
节 点: 构建群集的物理计算机
群集服务: 运行群集管理器或运行群集必须启动的服务
资 源: IP地址、磁盘、服务器应用程序等都可以叫做资源
共享磁盘: 群集节点之间通过光纤 SCSI 电缆等共同连接的磁盘柜或存储
仲裁资源: 构建群集时,有一块磁盘会用来仲裁信息,其中包括当前的服务状态各个节点的状态以及群集转移时的一些日志
资源状态: 主要指资源目前是处于联机状态还是脱机状态
资源依赖: 资源之间的依存关系
组 : 故障转移的最小单位
虚拟服务器: 提供一组服务--如数据库 文件和打印共享等
故障转移: 应用从宕机的节点切换到正常联机的节点
故障回复: 某节点从宕机状态转为联机状态后,仍然继续宕机前的工作,为其他节点分流
三、实验环境介绍及要求 1、拓扑图





七、故障转移测试 前面说了这么多,终于等到最激动人心的时刻了。在这一环节中,我准备将测试分为初级测试和高级测试两块来验证群集的故障转移功能。
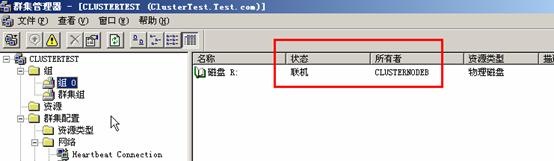
1、初级测试 (1) 打开群集管理器,从图中我们可以看出,目前数据共享磁盘的所有者是ClusterNodeA,状态为联机。
(2) 右键选择组0的“属性”,再选择“移动组”。
(3) 可以看到此时的状态为“脱机挂起”。
(4) 从图中可以得知,共享数据磁盘R的所有者已经转移到ClusterNodeB上了,状态为联机。
(5) 此实验说明,在群集服务中,资源能够从一个节点手动转移到另一个节点。(当然也能够自动转移,后面的实验均属于自动转移)
2、高级测试 (1) 手工模拟故障1次 (1) 打开群集管理器,对磁盘Q进行一次“初始故障”操作。此时磁盘Q的所有者为ClusterNodeA。
(2) 可以看到磁盘Q已经联机挂起了。
(3) 经过很短的时间后,磁盘Q又自动联机了,所有者还是ClusterNodeA。
(4) 此实验说明,群集节点的资源,在遇到初始故障后,能够自我修复,重新回到联机状态。虽然在这个实验中没有体现出能够初始故障多少次,但是我可以告诉大家,是3次。如果初始故障次数超过3次,就不会自我修复了,而是会进行故障转移。下面的实验会证明这一点。
(2) 手工连续模拟故障4次 (1) 打开群集管理器,对磁盘R进行“初始故障”操作,重复4次。此时磁盘R的所有者还属于ClusterNodeA。
(2) 4次模拟故障后,定位到“资源”,在右边窗口中可以看到,所有资源已自动迁移到ClusterNodeB上,处于联机状态。
(3) 由于心跳侦测机制的作用(心跳信息大约每1.2秒一次),群集服务会发现ClusterNodeA并不是真正的宕机,所以ClusterNodeA会自动尝试联机。
(4) 节点ClusterNodeA已恢复正常。
(5) 此实验说明,在群集服务中,当某个节点故障超过3次后,则不会自动恢复,而是进行故障转移。同时也说明,当群集服务检测到原节点可用时,原节点会再次自动回到群集中。此过程的专业术语叫“故障回复”
(3) 停止群集服务测试
[查看全文]










八、结束语 如果您完成了本指南全部的实验环节,那么恭喜您!您已经完成了所有节点上的群集服务配置。服务器群集已经完成可以运作了。您现在可以准备安装群集资源,比如:文件共享、打印机共享、诸如分布式的事务协调器、DHCP、WINS等群集识别服务、或者诸如Exchange Server或SQL Server等群集识别程序。
安装总结:
1.系统所有盘符必须格式化为NTFS格式;
2.当使用复制方式生成虚拟机式加入域后由于主机的SID,姓名公司等信息均相同需要使用工具修改并重新加入域否则,登陆域时“指定域的名称或安全标识SID与该域的信任信息不一致”
解决方法是:
①win2k3按装光盘support oolsdeploy.cab中提取sysprep.exe、setupcl.exe.
②运行,并在“选择不重置激活的宽限期” 重新封装 并重启,重启后会对SID、网络、电脑名字、公司名字等一些信息重新设置。
如下图所示,有一个选项是”重新启动“
在重新加入域之前,应该重新配置,修改pub网卡的IP属性
然后ping了半天,机器一直没有启来,看来是关机了,nnd,还得联系IDC机房帮忙重启。
既然是关机,干嘛要把重新启动写上去呢,害我关了好几台测试机,目前机器不够用了。
周末也不能接着赶文档了。真fuck。
以后有遇到同样问题的兄弟,请做好关机的觉悟。事先和IDC打个招呼,不要因为这点小事影响了项目进度。
[查看全文]
1) 在停止ClusterNodeB上的群集服务前,先打卡群集管理器,可以察看到,目前资源的所有者是ClusterNodeB。
2) 停止ClusterNodeB的群集服务。
3) 再次回到群集管理器,发现资源的所有者已经切换到ClusterNodeA上。因为ClusterNodeB上的服务已停止,不可能自动恢复过来。仍旧通过心跳侦测机制,当丢失4次心跳信息后,(大约5秒),则会宣告该节点失败。所以图中显示红叉,表示ClusterNodeB这个节点目前不可用。
4) 此实验说明,当某个节点上的群集服务停止后,运行在该问题节点上的资源会自动转移到其他正常节点。
(4) 模拟意外断电时故障转移 1) 测试前按照老规矩,打开集群管理器,可以看到资源的所有者是ClusterNodeB。
2) 直接关闭虚拟机后,打开ClusterNodeA上的集群管理器,发现资源已经为脱机状态,且群集组已显示不正常。
3) 群集服务试图将资源所有者切换到ClusterNodeA上。
4) 资源已全部迁移到ClusterNodeA上,且显示ClusterNodeB不正常。
5)此实验说明,当群集中的节点遇到突发性的意外事件(如意外断电等。)后,资源会自动从问题节点转移到正常节点。
[查看全文]




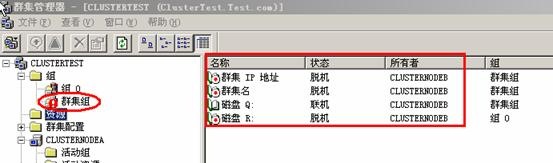


3、仲裁磁盘配置 启动“群集管理器”。右击左上角的群集名称,然后单击“属性”。单击“仲裁”选项卡。在“仲裁资源”列表框中,选择“磁盘Q”。
4、创建一个启动延迟(此操作非必需) 当出现所有的群集节点均同时启动并尝试附加到仲裁资源的情况时,群集服务可能无法启动。例如:在发生电源故障后,同时对所有节点恢复电力时,可能出现这种情况。(尽管可能性比较低,但是还是有可能发生的。)要避免这种情况,可以编辑boot.ini文件。将Timeout设置不同的值,以避免两个节点同时启动。
(1) 打开ClusterNodeA上系统盘根目录下的boot.ini文件,按下图修改。
也许您会问,为什么要添加一行同样的记录。这是因为如果是单操作系统,无论你如何设置timeout的值都是没有用的。只有多系统才会读取这个值。所以我们复制同样的记录来实现启动延迟的目的。
(2) 同样的方法,将ClusterNodeB上的boot.ini文件的timeout值设置为其他数值。如果您想在恢复电力时,ClusterNodeA能够优先启动,就把ClusterNodeB上的timeout值大于10。以错开同时启动。
5、测试群集安装 前面我们在CluterNodeA和CluterNodeB新建和加入现有群集结束后,都分别给出了一张截图用来验证群集安装的正确性。如果您觉得验证不周全,还可以采用如下几个方法来验证。
(1) 最简单的验证就是通过群集管理器。打开群集管理器,查看是否能够打开到群集的连接。
(2) 查看群集服务是否启动
(3) 相关事件日志
(4) 相关注册表键值
[查看全文]





